
Tag: gap statistics
-
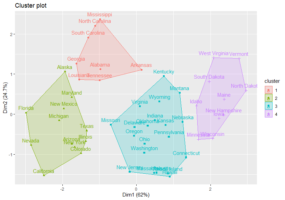
Clustering con algoritmo K-means
Estratto dal libro Data Science e Machine Learning: dai dati alla conoscenza Il K-means è un algoritmo di clustering partizionale in cui ogni cluster è associato ad un centroide ed ogni punto è associato al cluster col centroide più vicino. Il funzionamento di questo algoritmo richiede che il parametro k, indicante il numero di cluster…